1 计算机系统结构的基础知识
- 微程序架构:将一条机器指令编写成一段含有若干条微指令的微程序,由硬件解释执行
- 固件:固化的软件或具有软件功能的硬件,如驱动程序
- Flynn分类法:指令流和数据流的多倍性,包括SISD SIMD MISD MIMD
- 冯氏分类法:最大并行度表示同时处理一个字中的二进制位数乘上同时处理的字数;字串/并,位串/并
- 平均并行度、平均利用率
- Handler分类法:,k为程序控制部件个数,d为ALU或处理部件个数,w为基本逻辑线路套数
- 自顶向下设计、自底向上设计、从中间开始设计(从软硬件界面开始)
- Amdahl定律:
- CPU时间:CPU执行一个程序的总时间;区分CPU时间、CPI、IC等
- 性能指标:MIPS、MFLOPS、TOPS
- 执行时间、吞吐率
- 冯诺依曼架构:以运算器为中心
- 按机器档次:向上向下兼容;按时间:向前向后兼容
- 模拟:在宿主机上软件实现虚拟机的指令集;仿真:用宿主机微程序解释目标机指令集;仿真更快但要求指令集接近
- 并行的三种途径:时间重叠(主导)、资源重复、资源共享
2 指令系统的设计
- 指令系统的结构:堆栈结构、累加器结构、通用寄存器结构
- 寄存器-存储器结构、寄存器-寄存器结构
- 寻址方式:立即数寻址、直接寻址(偏移地址)、寄存器寻址、寄存器间接寻址(寄存器内部存储地址)、寄存器相对寻址、基址变址寻址(两个寄存器)、相对基址变址寻址
- 对指令系统的基本要求
- 完整性:足够使用
- 规整性:对称性(对寄存器的使用、操作码设置是对称的)、均匀性(对字长、操作数类型、操作种类等同等对待)
- 正交性(编码互不相关)
- 高效率
- 兼容性(向后兼容)
- 最短平均码长:
- 哈夫曼树
- 信息冗余量:(实际平均码长-最短平均码长)/实际平均码长
- 扩展操作码(2-4扩展操作码:码长2和4;2-4扩展码包括很多种扩展方式,例如3/4和1/12)
- 等长扩展码(15/15/15或8/64/512,表示每一级码长的编码个数)
3 流水线技术
- 空间并行性、时间并行性
- 连接图、时空图
- 功能段、流水寄存器
- 通过时间(第一个任务)、排空时间(最后一个任务)
- 流水线基本公式:
- 部件级流水线、处理器级流水线(指令流水线)、系统级流水线
- 单功能流水线、多功能流水线(静态、动态;区分标准为同一时段内是否只能执行一种功能)
- 线性、非线性(是否有反馈回路)
- 顺序流水线、乱序流水线
- 标量流水线、向量流水线
- 吞吐率:、加速比
- 解决瓶颈段:细分瓶颈段、重复瓶颈段
- 效率:使用的时空区除以总时空区
- 非线性流水线的预约表
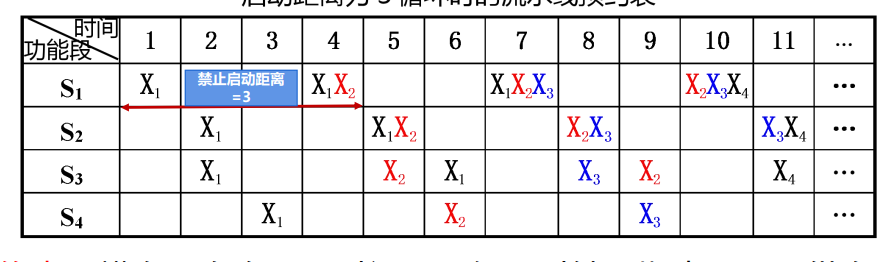
- 启动距离、启动循环(不发生冲突的启动距离的循环数列;包括恒定循环、简单循环)
- 算法:求最小启动循环
- 预留算法:插入非计算的延迟段,达到更优的调度
- 数据相关RAW、名相关(反相关WAR,输出相关WAW)
- 控制相关
- 结构冲突、数据冲突
- 分支指令:预测成功、预测失败、分支延迟(填充延迟槽:从前调度、从目标处调度、从失败处调度)
4 向量处理器
- 向量平衡点:向量部件和标量部件都充分利用的向量运算占比
- 向量表示法:等间距、带位移量、稀疏向量(使用压缩位向量)
- 横向处理方式(优先一个分量的多个指令)、纵向处理方式(优先一条指令的多个分量)、纵横向处理方式(分组)
- 存储体访问冲突:同时访问相同的存储体
- 存储器—存储器结构、寄存器—寄存器结构
- 向量处理机的主要冲突:寄存器冲突、功能部件冲突
- 使用多个独立的功能部件并行工作
- 向量流水线的链接:源向量、功能部件都不相同,有RAW冲突
- 向量流水线的通过时间和总时间计算
- ,为向量指令总时间,为建立时间,为通过时间,为时钟周期
- ,
- 编队:可以并行执行的向量指令;每个编队分别计算
- 分段开采技术:向量长度超过向量寄存器的长度,,为分组开采每个循环的额外开销
- 峰值性能:向量无限长时的最高性能,单位MFLOPS
- 半性能向量长度
- 向量长度临界值:向量计算优于标量计算的临界长度
5 指令级并行的硬件方法
- 指令调度的两个问题:程序顺序问题、控制相关问题
- 原则:数据流不变、异常行为不变
- 译码阶段分为流出(IS)、读操作数(RO),没有结构冲突即可流出,等待没有数据冲突再读操作数
- 乱序发射的冲突解决:RAW依靠读数等待,WAW依靠发射等待,WAR依靠寄存器重命名
- 记分牌算法
- 指令状态表:正在执行的各条指令执行到了哪一段(流出:无结构冲突、WAW冲突;读数:无RAW冲突;执行;写回:无WAR冲突),往往记录到达该段的周期数
- 功能部件状态表:每个功能部件包含Busy(忙),Op(正在执行的操作),F~i~(目的寄存器),F~j~,F~k~(源寄存器编号),Q~j~,Q~k~(提供F~j~和F~k~的部件),R~j~,R~k~(yes表示操作数就绪且未读,还需要前序部件的结果,否则置no)
- 结果寄存器状态表(产生当前寄存器值的部件)
- 显式动态寄存器重命名:维护一个从逻辑寄存器到物理寄存器的重命名表
- Tomasulo算法
- 保留站:Op,Q~J~,Q~k~(保留站号),V~J~,V~k~,Busy,A(L/S缓冲器存放地址),Q~I~(寄存器状态表)
- 用保留站名代替寄存器名
- 产生结果后通过公共数据总线广播,用结果替代之前的保留站名
- 重排序缓存 ROB
- 目的:按序发射、乱序执行、按序提交
- 使用循环数组,从队首提交
- 动态分支预测
- 转移预测缓冲器(n位,BHT)
- 相关转移预测器,(m,n)预测器设置2^m^个n-bit预测器,根据前m次转移的结果来预测
- 分支目标缓冲BTB:记录分支目标地址
- 可以通过ROB实现前瞻执行,在分支指令提交时清除错误的前瞻执行结果
- 超标量、超长指令字(超标量可以动态调度,超长指令字只能静态调度)
- 超流水线处理机:每1/n个周期流出一条指令
6 指令级并行的软件方法
-
循环展开
-
全局指令调度:跨分支结构的调度,核心思想为根据采取不同分支的概率来整体调度,可能需要增加补偿代码
-
踪迹:程序执行的指令序列,可以包括一个或多个基本块,可以包括分支但不能包括循环
-
踪迹调度:优化执行频率高的踪迹;踪迹可以有多个入口或多个出口
-
超块调度:限制踪迹只能有最多一个入口
-
显式并行指令计算EPIC:动态超标量和静态VLIW的中和
- 非绑定分支:将分支指令划分为粒度更小的指令
- 谓词执行:满足特定条件时才执行
- 前瞻执行
-
循环级并行:重点考虑循环携带相关
-
仿射数组的存储别名问题
-
值传播优化
-
高度削减优化:改变算式的结合方式,减小关键路径长度(减小计算树的树高)
-
软流水:从不同迭代中抽取指令拼成新的迭代;例如一个“取数→计算→存数”的循环过程,将其三步视为三个流水段,在软流水的一个迭代内执行“取x[i]、计算x[i+1]、存x[i+2]”,实现软件流水
7 存储系统
- 层次结构存储系统:M~i~层,访问时间T~i~,容量S~i~,总价格C~i~
- 局部性原理:顺序局部性、时间局部性、空间局部性
- 命中率、访问时间、访问效率
- 层次存储设计指标:相邻两级的访问速度差、相邻两级的存储容量差、预取数据块大小
- 映像规则:直接映像、全相联、组相联
- 查找算法:并行查找与顺序查找
- 替换算法:随机、FIFO、LRU
- FIFO和LRU的计数器法实现
- LRU法的比较对法实现,使用对触发器和与门
- 写命中策略:写直达、写回
- 写缺失策略:不按写分配(绕写法)、按写分配(写时取)
- 三种类型的缓存不命中:强制性不命中、容量不命中、冲突不命中
- 伪相联:先按直接映像找,没找到就去另一半区对应位置找
- 降低不命中率的软件优化:数组合并、内外循环交换、循环融合、分块
- 牺牲cache:在L1和L2之间放一个全相联小cache,存储从L1被换出的牺牲者
- 局部不命中率、全局不命中率
- 写缓冲、写缓冲合并技术、读不命中优先于写(读不命中时先读写缓冲器)
- 请求字处理技术:优先把CPU请求的字发给CPU
- 非阻塞cache:不命中不阻塞,处理不命中的同时允许其他命中访问
- 缓存的地址选取:物理cache、虚拟cache、虚拟索引物理标识
- cache访问需要多个周期时:流水化
- 踪迹cache:一种指令cache,存放近期CPU会执行的指令序列
- 并行主存系统:位扩展与字扩展(地址:字线;数据:位线)
- 单体多字存储器:一个存储器,一次读取出连续对齐的多个字
- 多体交叉存储器:多个单字存储体,每个存储体的读写独立;高位交叉:高位是体号,低位是体内地址;低位交叉:高位是体内地址,低位是体号;一个存储周期内分时启动存储体
- 避免存储体冲突(Bank Conflict);取模交叉:m个体,每个体n个单元,则体号为A mod m,体内地址为A mod n
- 虚拟存储:页式、段式、段页式
- 页面替换算法:RAND、FIFO、LFU、LRU、OPT
8 IO与互联网络
- 分离事务总线:有多个主设备时,通过包交换来分时占用(请求+应答)
- 同步总线/异步总线:是否有统一时钟
- I/O编址方式:MMIO或独立编址
- I/O控制方式:程序查询、中断、DMA、通道(一个特殊的处理I/O的处理机)
- 字节多路通道:每个外设传一个字节,设备选择时间,传输一个字节的时间,个外设,每个传送字节,则总时间,最大流量:
- 选择通道:一段时间内只为一个外设服务,省去一些选择时间,
- 数组多路通道:每个大小的块完成一次选择,
- 互联函数:连接到
- 恒等函数
- 交换函数:Cube~i~反转第i位
- 均匀洗牌函数:循环左移一位
- 蝶式互连函数:交换首末位,子函数、超函数
- 反位序函数
- 移数函数PM2~+i~、PM2~-i~
- 互联网络结构参数:规模N、结点度d、结点距离、直径D、等分宽度b(等分切口边数最小值)、对称性
- 互联网络性能指标:通信时延(软件开销、通道时延、选路时延、竞争时延)、网络时延(通道时延+选路时延)、端口带宽、聚集带宽(一半结点到另一半结点的最大带宽)、等分带宽(等分宽度对应的切面的带宽)
- 静态互联网络
- 线性阵列
- 环、带弦环
- 全连接
- 循环移数网络
- 树形、星形
- 网格形
- Illiac(按列首尾相连、按行整体成环)
- 环网形
- 超立方体
- 带环立方体k-CCC(规模为)
- k元n-立方体网络()
- 动态互联网络
- 交叉开关网络
- 多级互连网络(级控制、部分级控制、单元控制),STARAN网络、Omega网络
- 消息传递机制:寻径方案
- 线路交换:先发寻径包建立通路,然后直接发包,
- 存储转发:
- 虚拟直通:类似线路交换,先发包头,只存储转发包头
- 虫蚀:一个片一个片传递,
- 消息传递可能产生死锁
- 包冲突(两个包同时到达)的解决:缓冲、阻塞、丢弃重发、绕道
- 确定性寻径、自适应寻径
- X-Y寻径:建立在二维网格上,先走X再走Y
- E-cube寻径
- 通信模式:单播、选播、广播、会议
9 多处理机
- MIMD架构:集中式共享处理器(SMP、UMA),分布式存储器多处理机
- 存储器系统:共享地址空间(物理上分离,逻辑上统一,NUMA),独立地址空间
- 并行处理中的Amdahl定律
- Gustafson定律:并行部分扩大倍时加速比随之增长
- 多处理机缓存一致性问题
- 监听式协议:请求在总线上广播,监听总线;缓存块状态转换同时受当前处理器的请求和来自总线的监听信号的影响;未缓存I,共享S,独占M
- 目录协议:维护一个缓存块共享状态目录;全映像目录、有限映像目录(限制一个块的副本总数)、链式目录;未缓存U,共享S,独占E
- 写作废协议、写更新协议
- 用于同步的基本硬件原语(原子操作):原子交换、测试并置定、读取并加1、使用指令对LL SC
- 细粒度多线程、粗粒度多线程,区别在于何时可以切换线程
- 同时多线程:对于超标量处理器,同一个周期的多个流出槽可以由不同线程使用
- 大规模并行处理机:并行向量处理机PVP,对称式共享存储器多处理机SMP,分布式共享存储器多处理机DSM,大规模并行处理机MPP,机群计算机Cluster