高性能计算简介
高性能计算的核心是并行处理
高性能计算的三个目标:
- 算的更快:提升求解速度
- 算的更多:提升问题规模
- 算的更好:提升求解精度
高性能计算的衡量单位:
- 计算能力,Flop/s:浮点数运算每秒
- 存储能力,B:字节
高性能计算硬件
高性能计算机(超级计算机):一般为多个多核服务器通过高速网络互连组成的系统,称为集群架构(cluster)
多核服务器:包含CPU、内存、存储、加速器、网卡
- 使用并行文件系统,存储节点独立于计算节点,与计算节点通过高速互联网络处理IO
- 网络使用比以太网更加快速、短程的Infiniband(IB),核心技术为远程直接内存访问(RDMA)
并行计算硬件模型
Flynn分类法
并行计算硬件模型的Flynn分类法:从处理单元的角度考虑指令流和数据流
- SISD:单指令流、单数据流
- 单核处理器
- SIMD:单指令流、多数据流
- 例如CPU中的向量处理单元、GPU
- 可以并行操作数据
- MISD:多指令流、单数据流
- 实际应用很受限
- MIMD:多指令流、多数据流
- 现代计算机、多核处理器
内存视角分类
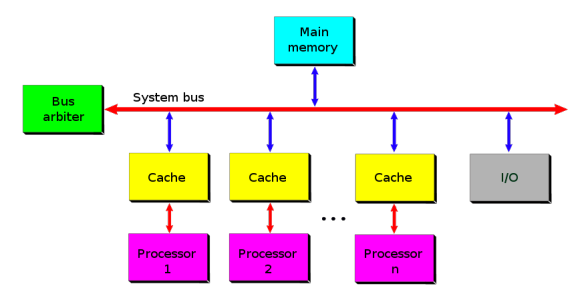
共享内存:
- 所有处理单元与共享内存相连,处于同一地址空间
- 任何处理单元可以直接访问任何内存位置
- 均匀内存访问架构(UMA):每个处理器访问每个地址的性能相同
- 非均匀内存访问架构(NUMA):每个单元有局部内存,访问局部内存优于访问远程内存;可以拓展到很大规模
分布式内存:
- 每个处理单元拥有自己的内存,不同内存地址空间独立
- 数据传输不能直接访问,需要显式通信
对称多处理器(SMP)
- 包含多个相同处理器,连接到一个共享内存
- 多个处理器是同构、对称的
- 可以同时处理不同任务
单芯片多处理器(CMP)
- 将SMP技术应用到单个处理器内,也叫多核处理器
并行编程模型
共享内存模型
不同指令流并发执行
指令流之间的同步采用共享变量
数据存放在单一地址空间,不需要显式通信
适用共享内存架构的硬件模型(例子:多线程 )
进程:进行数据隔离
线程:在进程内部进行指令流隔离
例子:pthread、OpenMP
消息传递模型
不同指令流并发执行
指令流之间的同步基于通信
数据存放在不同指令流的独立地址空间,需要显式通信
适用分布式内存架构或共享内存架构
使用MPI作为事实标准,MPI有不同实现
数据并行模型
在不同数据上执行相同逻辑,逻辑上只有一个指令流,操作多份数据
适用SIMD或分布式内存架构
例子:向量扩展指令、MapReduce编程模型
MapReduce:对向量输入的计算分为两个阶段
- Map:以相同的逻辑处理输入中的每个元素,即“映射”
- Reduce:综合映射得到的中间结果,得到最终结果
混合多种并行编程模型
实际使用中往往混合应用,例如分布式深度学习训练:
- 节点间采用消息传递模型
- 节点内采用三种模型综合
科学计算中,使用超大规模集群、多核节点、异构计算设备
并行计算性能指标
加速比:
- 为串行时间,为并行时间,为处理单元数目
- 线性加速:,为理想情况的最大加速比
- 超线性加速:,实际情况中有时会发生
- 亚线性加速:,是典型的情况
难以实现理想线性加速的原因:
- 程序不是所有部分都可以并行
- 并行处理引入通信和同步开销(比较重要)
- 并行可能引入额外计算(比如重复计算)