属性文法
在上下文无关语言的基础上,为每个文法符号关联属性(Attribute),并且为每个产生式关联一个语义规则集合或语义动作
属性可以是任何与文法符号相关的特性,文法符号的属性用表示
属性文法中,使用语义规则来访问、改写属性,其简单的形式为覆写,例如:
更加复杂的形式可以涉及语义函数,即产生式中各个文法符号的属性的函数:
根据上面的语义规则,可以将属性分为两类:
- 综合属性:是产生式左侧符号的属性
- 继承属性:是产生式右侧某个符号的属性
属性文法的一个简单例子如下:
这展示了对于一个纯加法表达式,由词法分析得到的属性计算表达式结果的过程
注意,上面文法中和均代表非终结符,引入下标只是为了对来自不同非终结符的属性进行区分
上述属性文法只含有综合属性,可以通过自底向上遍历语法分析树(即归约)直接计算出表达式的结果,也即:在语法分析的同时完成了语义计算,这就是所谓“语法制导的语义计算”中制导的含义
然而,属性文法可能不止含有综合属性,对于含有继承属性的情况,难以在简单的归约分析过程中完成全部语义计算
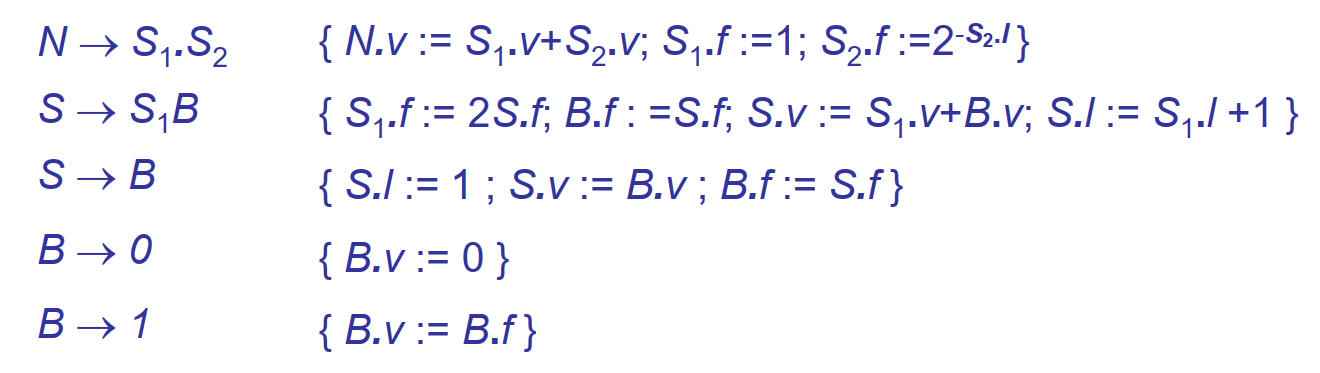
例如对上述同时含有综合属性和继承属性的文法(开始符号为),它的语义功能为计算二进制小数的值,具体属性含义如下:
- 表示符号对应串的位数
- 表示符号对应串的最低位位权,即整个串求值时乘以的倍率
- 表示符号对应串的求值(已考虑位权的情况下)
上述属性文法可以采取以下的计算顺序:
- 自底向上计算小数部分的
- 由起始产生式计算出小数部分的位权
- 自顶向下传递位权
- 自底向上计算符号的
- 由起始产生式拼接整数部分和小数部分
这经历了一个相对复杂的多遍遍历过程
基于属性文法的语义计算
树遍历方法
树遍历方法的具体步骤如下:
- 构造语法分析树
- 构造各个属性之间的依赖图
- 如果依赖图无环,则可以对该图进行拓扑排序,以此顺序遍历分析树即可计算所有的属性
如果依赖图有环,则属性文法不是良定义的,即它的属性值可能存在因循环依赖而无法确定的情况
关于有向无环图(DAG)和拓扑排序可以参考拓扑排序 - OI Wiki
依赖图的构造
依赖图构造算法为
- 对分析树中的每一个节点
- 为该节点所用产生式中每个语义规则涉及的属性建立节点
- 为该节点所用产生式中每个无返回语义函数(形如,但并未覆写某个属性)建立节点,这种节点被称为虚节点
- 对分析树中每一个节点的产生式中的每一条语义规则
- 若语义规则为无返回的语义函数,则视为该函数的虚节点
- 从每个向建立有向边
树遍历方法的能力和不足
从上面的讨论可以看出,树遍历方法可以对任何良定义的属性文法进行语义计算,得到的结果为带标注的(annotated)语法分析树
然而,树遍历方法可能会对很多节点进行多次遍历,并且往往需要先生成语法分析树再进行遍历,复杂度较高
正如我们希望语法分析过程能够单遍完成一样(为此我们研究了诸如LL(1),LR(0),LR(1)等语法分析方法),我们同样希望语义计算可以单遍完成,但这自然会对属性文法做出约束
单遍方法
我们对属性文法做出以下约束:
- S-属性文法:只含综合属性
- L-属性文法:可以同时包含综合属性和继承属性,但
- 任何继承属性的计算只取决于该属性所属的符号左边的符号的属性
S-属性文法的语义计算
可以利用LR分析技术,自底向上进行,具体地:
- 扩充分析栈,使之包含存放综合属性值的语义栈
- 在决定利用产生式归约的时刻进行语义计算
L-属性文法的语义计算
利用LL分析技术,在推导时计算每个右端符号的继承属性,在完成每个右端符号的分析时计算左端符号的综合属性
基于翻译模式的语义计算
翻译模式是一种比属性文法在计算顺序上更加严格的描述方式,具体地:
- 与属性文法相同,使用在文法的基础上附加花括号标出的语义规则集的形式
- 与属性文法不同的是,语义规则集可以出现在产生式右端任何位置,可以显式表示计算次序
与属性文法类似,翻译模式需要受到一定的限制才可以单遍分析,具体地:
- 类似S-属性文法,仅包含综合属性,且对综合属性的计算放在产生式末尾
- 类似L-属性文法,既包含继承属性又包含综合属性,但每个符号继承属性的计算必须在到达该符号之前,且计算式只访问左侧符号的属性;综合属性的计算放在产生式尾部
下面是一个翻译模式的例子,它对应于之前的二进制小数值计算的属性文法:

自顶向下语义计算
自顶向下的预测分析程序中,只需要在翻译模式中语义规则集对应的位置插入语义计算的指令即可
值得注意的是:
- 原先的
parseS函数将以S的综合属性作为返回值,以其继承属性作为函数参数 - 自顶向下语义计算使用LL(1)方法,故有时需要消除左递归,在消除左递归时需要对语义规则集进行一些调整
翻译模式的左递归消除
考虑以下左递归的翻译模式:
则句型的语法分析树如下:
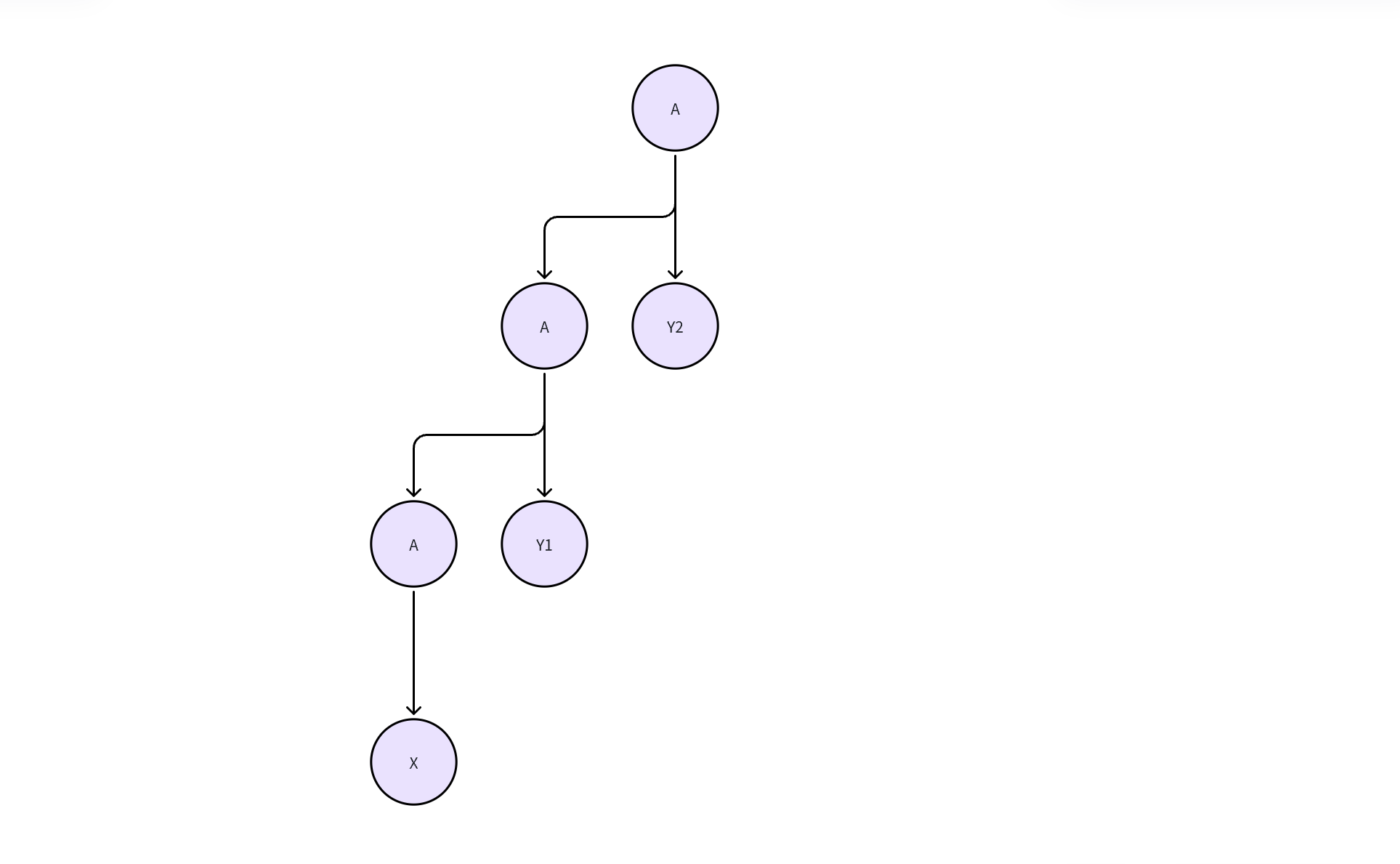
综合属性的计算发生在每个推导结束时
然而,消除左递归将文法变为
则语法分析树变为下图中右侧的结果:
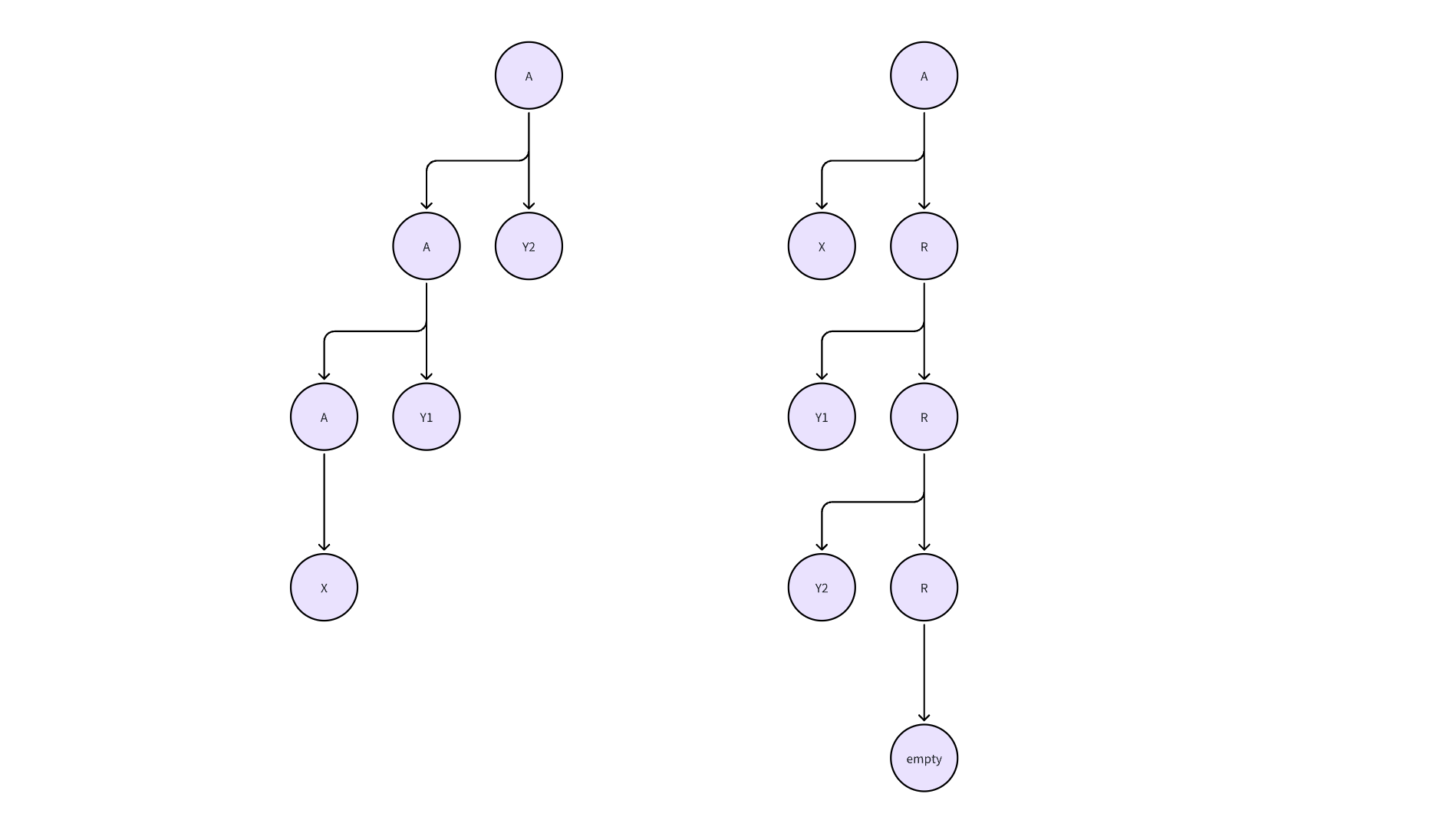
注意到这其实是对原先的树进行了一个类似数据结构中Splay的操作,此时、、在树中的高低位置反转
为此,原先以综合属性的形式计算的的属性在右图中必须作为的继承属性,并且在达到树底的时候再以综合属性的形式将的属性上传,回到
于是,消除左递归后的翻译模式如下:
注意到综合属性只起到了将属性值从底部传回顶端的作用,而和则是对原先翻译模式中的模拟
事实上,原始翻译模式中的表示的是其子树的属性;而新翻译模式的表示的是其所有左侧枝(左侧兄弟和所有祖先的左侧兄弟)的属性
自底向上语义计算
L-翻译模式的自底向上计算比较复杂,介绍以下三个方面:
- 去掉嵌在产生式中间的语义动作
- 分析栈中继承属性的访问和继承属性的模拟求值
- 用综合属性替代继承属性
在这三个方面中,我们会涉及一些相当简单的例子的讨论
去掉嵌在产生式中间的语义动作
动机:由于LR分析在读入短语后才具有选择归约产生式的能力,因此LR分析不能执行产生式中间的语义动作
做法非常简单:将产生式中间的语义动作用非终结符代替,同时加入产生式,将上面去掉的语义动作放在这个产生式的末尾
例如:
改为
分析栈中继承属性的访问
动机:上面的步骤可以简单地处理不涉及继承属性的内嵌语义动作,但当语义动作涉及左侧符号的继承属性时,问题会变得比较复杂——这是因为LR分析通过分析栈存放属性,但语义动作计算出的继承属性属于一个不存在于栈中且不一定会马上入栈的符号(与之相比,综合属性所属的符号会在归约后马上入栈,因此可以将计算出的综合属性入栈)
考虑以下翻译模式:
注意到:
- 这里所有场景下出现的都等于开始的综合属性
- 每次出现函数对的引用,都在栈上某个固定的位置,用表示栈顶指针,则
- 对产生式2,就是
- 对产生式3,就是
即:我们使用栈上相对栈顶指针的深度一定的某个符号的综合属性来替代语义规则中引用的难以寻址的继承属性
在生成分析程序时,函数的参数并不直接传入捉摸不定的,而是传入上述的由指针指向的综合属性
继承属性的模拟求值
动机:上面的做法局限性很大,体现在——要求每个被引用的继承属性都能用某个栈上固定深度的综合属性表示;但这对很多翻译模式并不现实
例如,考虑以下的翻译模式:
注意到,在函数引用时,总是体现为某个,但这里的可能在(对产生式1),也可能在(对产生式2),而产生式1和产生式2
我们希望让这里的总是存在于,为此,需要在产生式2的后面引入新的虚拟非终结符,具体如下:
于是,对产生式2,改为使用而不是,解决了上面的问题
然而,上面只解决了引用的继承属性位置不确定的情况,但还可能出现引用的继承属性不在栈上的情况,即继承属性并不直接等于某个综合属性,具体例子如下:
这里的虽然由栈上属性决定,但并不真实存在于栈上
将翻译模式改为:
就解决了这一问题,即引入虚拟非终结符用来存储
总结
上面几个部分中,最重要的策略就是引入虚拟非终结符
虚拟非终结符是我自创的词汇,它表示那些没有语法功能(即唯一产生式是)但有语义功能(即承担内嵌语义动作消除或继承属性定址等方便LR分析器进行语义计算的功能)
然而,更聪明的办法或许是直接修改翻译模式,使继承属性变成综合属性